Question 19
An administrator is troubleshooting vDisk performance issues in a Nutanix cluster with hybrid disks. The VMs all have Flash Mode enabled.
But users are reporting disk latency.
What could cause the performance issues?
Correct Answer:D
data size for flash mode exceeds 25% of the SSD capacity could cause the performance issues. Flash mode is a feature that allows vDisks to be pinned to SSDs for faster access, but it has a limit of 25% of the SSD capacity per node. If this limit is exceeded, some vDisks may be evicted from flash mode and cause disk latency2.
Question 20
Refer to Exhibit: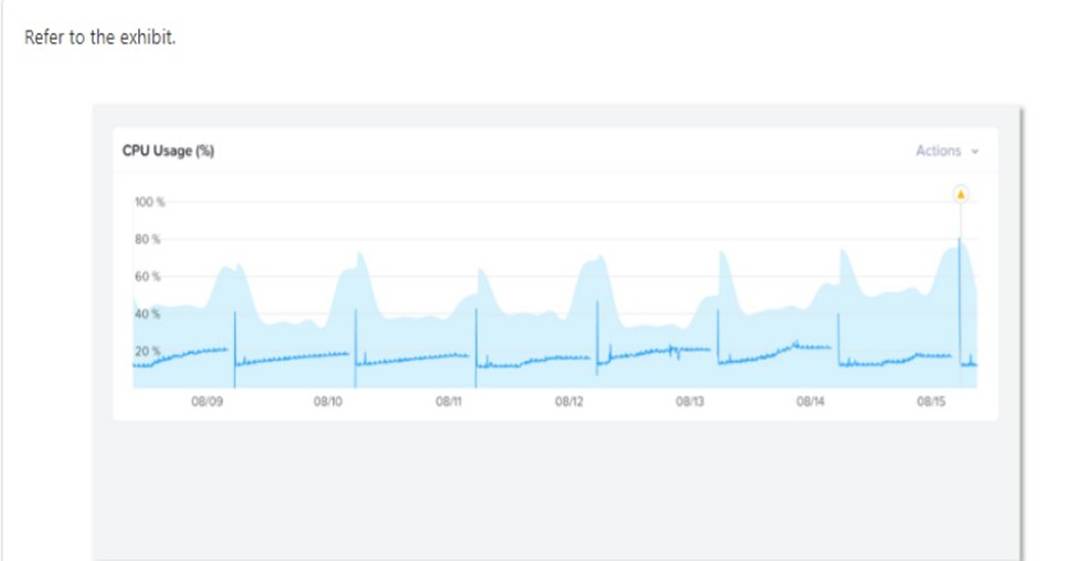
Why has an anomaly been triggered?
Correct Answer:A
Nutanix leverages a method for determining the bands called ??Generalized Extreme Studentized Deviate Test??. A simple way to think about this is similar to a confidence interval where the values are between the lower and upper limits established by the algorithm.
Another web source3 shows an example of how anomaly detection works in Nutanix Prism Central. In the video, you can see that when the observed value of a metric deviates significantly from the predicted value based on historical data, an anomaly event is triggered and displayed on a chart.
Therefore, by comparing the observed values with the predicted values based on historical data, Nutanix anomaly detection can identify abnormal behavior and alert you accordingly.
Question 21
What is the name of the internal bridge used by AHV nodes and CVMs?
Correct Answer:C
According to the Nutanix Support & Insights web search result1, the name of the internal bridge used by AHV nodes and CVMs is br0. The internal bridge is an Open vSwitch (OVS) bridge that connects the AHV host management interface, the CVM
interface, and the VM vNICs. The internal bridge also acts as a gateway for the CVM and VM traffic to reach the external network through the host physical NICs.
Question 22
Refer to Exhibit.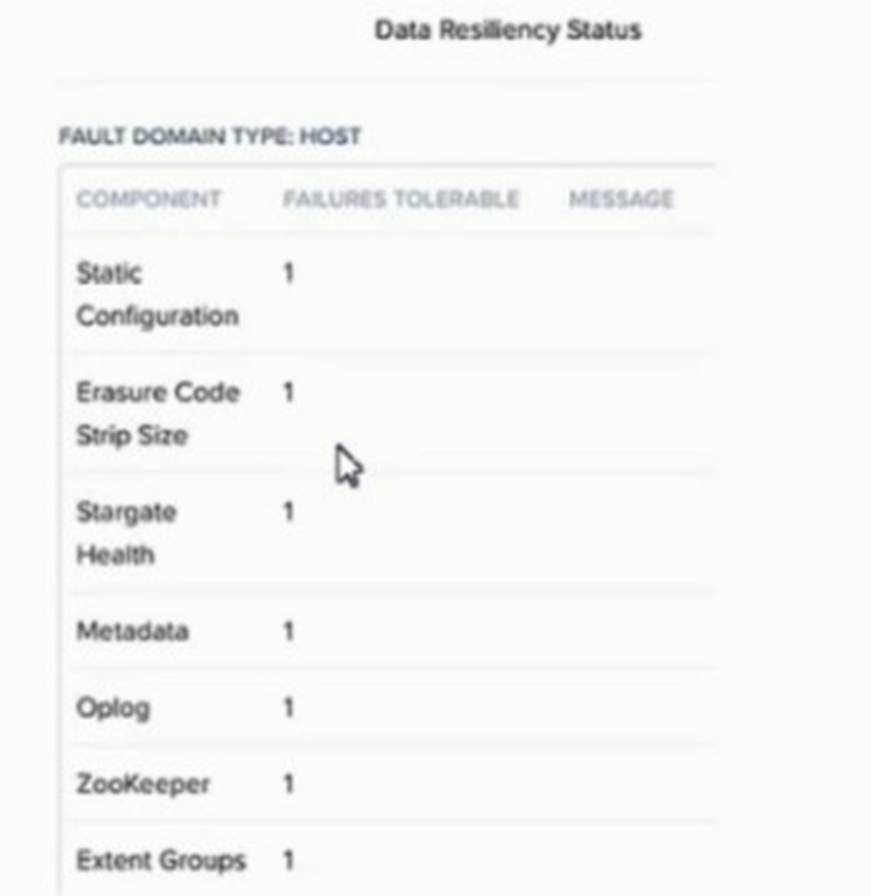
An administrator increases the cluster RF to 3. The containers are not modified.
What will the new values in the data resiliency dashboard be for FAILURES TOLERABLE for the Zookeeper and Extent Groups components?
Correct Answer:C
According to the web search results, the cluster redundancy factor (RF) determines how many copies of the cluster metadata and configuration data are stored on different nodes. By default, the cluster RF is 2, which means that there are three copies of the Zookeeper and Cassandra data on the cluster. If the cluster RF is increased to 3, then there will be five copies of the Zookeeper and Cassandra data on the cluster12. This means that the Zookeeper component can tolerate two failures, as it can still operate with a quorum of three nodes out of five3.
However, the container replication factor (RF) determines how many copies of the VM data and oplog are stored on different nodes. The container RF can be set independently for each container, and it can be different from the cluster RF. For example, a container can have RF 2 even if the cluster has RF 34. In this case, the container will only have two copies of the VM data and oplog on the cluster, regardless of the cluster RF. This means that the Extent Groups component can only tolerate one failure, as it needs at least one copy of the VM data and oplog to be available5.
Therefore, if the administrator increases the cluster RF to 3, but does not modify the containers, then the new values in the data resiliency dashboard will be Zookeeper = 2 and Extent Groups = 1.
Question 23
HOTSPOT
What is the proper sequence to perform a one-click upgrade to a Nutanix cluster?
Item instructions: For each procedure, indicate the order in which that procedure must take place to meet the item requirements. Not all procedures are valid. Identify any invalid procedures using the drop-down option.
Solution:
Step 1 ---> Login into Prism Element.
Step 2 ---> Select the Gear Icon at top right of the page.
Step 3 ---> Click Upgrade Software.
Step 4 ---> Select the component to upgrade.
Step 5 ---> Click download.
Step 6 ---> Once the download completes, select upgrade.
Invalid:-
1 - Select Prism Central. 2 - Select user login. 3 - On left select upgrade Prism Central.
Does this meet the goal?
Correct Answer:A
Question 24
Which command should an administrator run from the CLI to view the uplink state of all AHV nodes in the cluster?
Correct Answer:C
According to section 4 of the exam blueprint guide1, one of the topics covered is AHV networking components and configuration settings. One of these components is Open vSwitch (OVS), which is a software switch that provides network connectivity between VMs and physical networks. OVS has two types of ports:
✑ Uplink ports: These are physical ports that connect to external networks or
switches.
✑ Internal ports: These are virtual ports that connect to VMs or other internal networks.
To view the uplink state of all AHV nodes in the cluster, an administrator can use the manage_ovs command with the show_uplinks option. This command displays information such as port name, link state, speed, duplex mode, MTU size, bond mode, and bond status. However, this command only works on a single node. To run the command on all nodes in the cluster, an administrator can use the allssh command, which executes a command on all CVMs in parallel. Therefore, the correct command is:
allssh manage_ovs show_uplinks